What is Ripple Down Rules (RDR)?
Proposer: Paul Compton
Ripple-Down Rules (RDR) is a strategy of bulding systems incrementally while they are already in use. When a system does not deal with a case or situation correctly a change is made in such a way that the previous competence of the system is not degraded. The change is mades simply and rapidly and the difficulty of making a change should not increase as the system develops. RDR can be categorised as a type of apprentice learning
Various commercial RDR systems have been developed for a range of applications. There have have been research proofs for a wide range of applications including: various types of classification problem, configuration or parameter tuning, text-processing, image processing, heuristic search, tuning genetic algorithms and multi-agent environments. There have also been machine-learning versions of RDR.
A number of researchers at UNSW and elsewhere have been involved in this research. Current research is aimed extending the range of possible applications of RDR and further integration with machine learning so that a system knows when it cannot deal adequately with a problem and needs further training and can discuss the situation with its trainer.
The focus of this work has mainly been knowledge-based system. The approach seems even more essential when one considers the increasing significance of preference-based systems, either personal or business preferences with applications across web services. The ultimate goal is a general software engineering solution whereby all systems can be easily evolved as requiremente evolve and further requirements emerge.
References
- "Paul Compton's website", Ripple-Down Rules summary, Retrieved February, 2013
- Compton, P., & Jansen, R. (1990). A philosophical basis for knowledge acquisition. Knowledge acquisition, 2(3), 241-258. [[Paper Link]]
- Compton, P., Peters, L., Edwards, G., & Lavers, T. G. (2006). Experience with ripple-down rules. Knowledge-Based Systems, 19(5), 356-362. [[Paper Link]]
- Compton, P., Cao, T., & Kerr, J. (2004). Generalising incremental knowledge acquisition (Doctoral dissertation, School of Computing, Unviersity of Tasmania). [[Paper Link]]
What is Multiple Classification Ripple Down Rules (MCRDR)?
Proposer: Byeong Ho Kang
The aim of MCRDR is to preserve the advantages and essential strategy of RDR
in dealing with multiple independent classifications. MCRDR, like RDR, is
based on the assumption that the knowledge an expert provides is essentially
a justification for a conclusion in a particular context. A major component of
the context is the case which has been given a wrong classification and how
this differs from other cases for which the classification is correct. As we shall
see, the context in MCRDR is preserved differently and only includes rules
that have been satisfied by the data and validation extends to differentiating
the new case from a range of different cases.
1)Inference
The RDR inference operation is based on searching the KB represented as a
decision list with each decision possibly refined again by another decision list.
Once a rule is satisfied no rules below it are evaluated. In contrast MCRDR
evaluates all the rules in the first level of the KB. It then evaluates the rules at
the next level of refinement for each rule that was satisfied at the top level
and so on. The process stops when there are no more children to evaluate or
when none of these rules can be satisfied by the case in hand. It thus ends up
with multiple paths, with each path representing a particular refinement
sequence and hence multiple conclusions.
The structure of an MCRDR knowledge base can be drawn as an n-ary tree
with each node representing a rule. Fig 1 shows such a structure and also
shows the inference for a particular case.
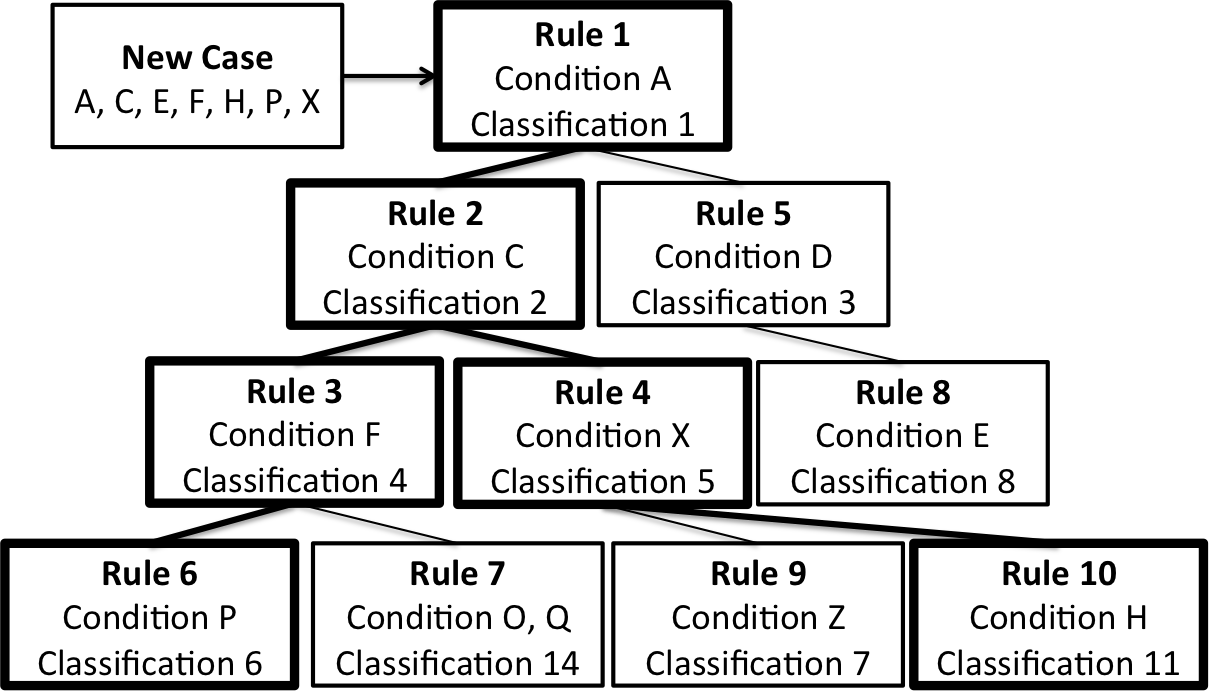
Fig1. MCRDR Inference example
2)Knowledge Acquisition
When a case has been classified incorrectly or is missing a classification,
knowledge acquisition is required and can be divided into three parts. Firstly,
the system acquires the correct classifications from the expert. Secondly, the
system decides on the new rules' location. Thirdly, the system acquires new
rules from the expert and adds them to correct the knowledge base.
It is likely that experts may find the system more natural if the order of steps
two and three are reversed, thereby better hiding the implicit knowledge
engineering that is going on. However, the order is not crucial in terms of the
algorithm.
2.1. Acquiring New Classifications
Acquiring new classifications is trivial, the expert simply needs to state them.
For example, if the system produces classifications class 2 , class 5 , class 6
for a given problem , the expert may decide that class 6 does not need to be
changed but class 2 and class 5 should be deleted and class 7 and class 9
added.
2.2.Locating Rules
The system should find the locations for the new rules that will provide these
classifications. It cannot be assumed that the correct location for a new rule is
as a refinement for one of the rules giving one of the wrong classifications. It
may be a quite independent classification and the wrong classification is
simply wrong. The possibilities are shown in Table 1. Note the idea of
stopping rules, rules that make no conclusion, or rather give a null
classification. Stopping rules play a major role in MCRDR in preventing wrong
classifications being given for a case.
As well as attempting to decide whether a classification is best seen as a
refinement or an independent classification, we note that in some ways it does
not matter - both are workable solutions for any classification. The key effect
of the rule location is to effect the evolution and maintenance of the
knowledge base. If there is a strategy that tends to add rules at the top level,
the knowledge base will cover the domain more rapidly but with a greater
likelihood of error. If the strategy tends to add new rules at the end of paths,
domain coverage will be slower but with less errors from the new rules, simply
because they see less cases . A rule can also be placed
at appropriate intermediate levels. One can also change these strategies as the
system develops. These decisions are a new type of knowledge engineering consideration - the issue is what type of development is appropriate for a particular domain, rather than the structure of the knowledge.

Table1. MCRDR Inference example
Decisions about the evolution of the knowledge base do not have to be
knowledge engineering decisions that override any preferences of the expert.
Rather, the expert can be free to make any type of decision, but the interface
can be designed so that the expert is more likely to add rules towards the top
or the bottom. For example, two alternative strategies might be to ask the
expert to select the important data used in reaching the conclusion or to
delete the irrelevant data. If selected data satisfies a pathway the rule is
placed at the bottom of the pathway or at whatever level the conditions
selected reach down to. One may expect that the expert's behaviour will be
conservative, he or she will either select few conditions or remove few
conditions. The method used here is for the (simulated) expert to select
important data in the case. We call the selected conditions a "mini-case".
Other strategies may include asking the expert to make the normal difference
list selection (see below) and then asking the expert to select from a list which
includes all the conditions for all the possible pathways where the rule may
go. Again the expert's behaviour can probably be biased by asking for
conditions to be removed or alternatively selected. In this paper we have not
explored these strategies further as they do not determine whether or not the
method works, they merely help tune it to a particular domain problem and
application
References
- Kang, B., Compton, P., & Preston, P. (1995, February). Multiple classification ripple down rules: evaluation and possibilities. In The 9th Knowledge Acquisition for Knowledge Based Systems Workshop. [[Paper Link]]
- Yoon, H., Han, S. C., Kang, B. H., & Park, S. B. (2012). V&V to Use Agile Approach in ES Development: Why RDR Works for Expert System Developments!. Computer Applications for Software Engineering, Disaster Recovery, and Business Continuity, 113-120.[[Paper Link]]